-
K-Fold 교차 검증IT/Programming 2022. 1. 21. 20:27
k-fold 교차 검증
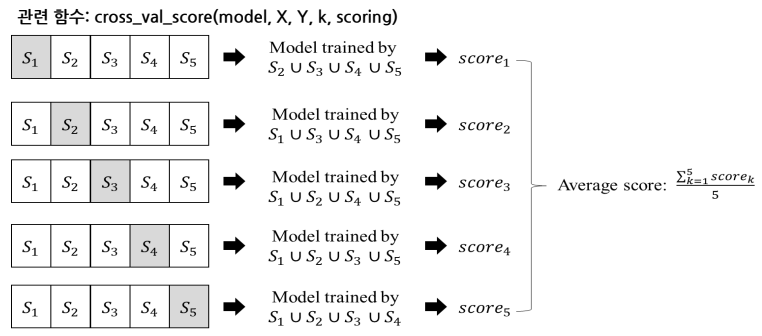
- 데이터를 k 등분하여 k번 모델링을 통해 모델을 평가하는 방법
- 5등분해서 하나를 test 데이터(회색) 나머지(흰색)을 train 데이터로 사용.총 5번 반복
- 생성된 5개 모델링 스코어를 바탕으로 평균 스코어를 계산해 모델을 평가
- 5개 스코어 중 제일 높을 걸 골라 최종 모델로 사용할 수 있음. 또한 만족스러운 스코어가 나왔다면 S1~S5까지의 데이터를 합쳐 모델 학습에 이용할 수도 있음.
- k-fold 는 실제적으로는 잘 쓰이지는 않는다. k-fold에는 일반적인 train-test-val 과 달리 셔플옵션이 없기 때문이다. 따라서 학습 시에는 점수가 높은데 실제 k-fold 수행 점수는 낮은 현상이 간혹 발생한다. 셔플을 하고 싶으면 x와 y를 인위적으로 shuffle해준뒤 k-fold 를 하면 보완은 된다.
 import seaborn as sns iris = sns.load_dataset('iris') X_iris = iris.drop('species', axis=1) y_iris = iris['species']# KNN 모델 인스턴스화 from sklearn.neighbors import KNeighborsClassifier model1 = KNeighborsClassifier(n_neighbors=1) model2 = KNeighborsClassifier(n_neighbors=3)# 5-겹 교차 검증 from sklearn.model_selection import cross_val_score scores1 = cross_val_score(model1, X_iris, y_iris, cv=5, scoring = 'accuracy') scores2 = cross_val_score(model2, X_iris, y_iris, cv=5, scoring = 'accuracy') print('scores1 : ', scores1.mean()) print('scores2 : ', scores2.mean())
import seaborn as sns iris = sns.load_dataset('iris') X_iris = iris.drop('species', axis=1) y_iris = iris['species']# KNN 모델 인스턴스화 from sklearn.neighbors import KNeighborsClassifier model1 = KNeighborsClassifier(n_neighbors=1) model2 = KNeighborsClassifier(n_neighbors=3)# 5-겹 교차 검증 from sklearn.model_selection import cross_val_score scores1 = cross_val_score(model1, X_iris, y_iris, cv=5, scoring = 'accuracy') scores2 = cross_val_score(model2, X_iris, y_iris, cv=5, scoring = 'accuracy') print('scores1 : ', scores1.mean()) print('scores2 : ', scores2.mean())
그리드 서치
- 여러 모델, 모델에 해당되는 파라미터의 조합을 통한 모델링 방법을 통해 최적의 모델을 선정
하는 방법
- 조합(전처리 방법 x 모델 종류 x 모델 파라미터 x k-fold 등 조합의 수가 매우 많아질 수 있음)이 많아질수록 성능이 좋은 파라미터를 찾아낼 확률이 높아지지만 그만큼 시간이 오래 걸린다는 단점이 있음.

'IT > Programming' 카테고리의 다른 글
Python #2] 파이썬을 활용한 크롤링(crawling) (0) 2020.01.15 Python #1] Python 개발환경 설치하기 (0) 2020.01.15 error LNK2019: unresolved external symbol "__declspec(dllimport) (0) 2009.04.17 문자열 변환 (0) 2008.11.28