-
Python #2] 파이썬을 활용한 크롤링(crawling)IT/Programming 2020. 1. 15. 18:34
크롤링(crawling)
Web상에 존재하는 Contents를 수집하는 작업으로, 프로그래밍을 활용한 자동화 기능이다.
HTML 페이지를 가져와서, HTML/CSS등을 파싱하고, 필요한 데이터만 추출하는 기법이다.
Open API(Rest API)를 제공하는 서비스에 Open API를 호출해서, 받은 데이터 중 필요한
데이터만 추출하는 기법으로, 브라우저를 프로그래밍으로 조작해서 필요한 데이터만 추출하는 기법크롤링 기능을 제공하기 위해 BeautifulSoup 라이브러리를 먼저 설치해 보자
Python 이 설치한 폴더의 하위 폴더에 Script 폴더로 이동한 후에, 아래와 같이 requests 와 BeautilfulSoup 라이브러리를 설치한다.
pip install bs4
pip install BeautifulSoup이제 아래와 같이 requests 와 BeautifulSoup 라이브러리를 활용해서 웹 페이지를 읽은 후에 title 태그의 내용을 출력하는 예제를 출력해 본다. 이 예제는 news.naver.com 웹 페이지의 title 태그의 내용을 크롤링 하는 예제이다
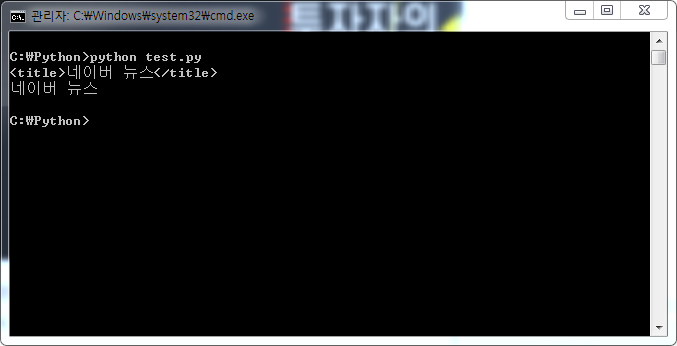
get_text() 함수를 사용하면 html 코드는 제거하고 텍스트만 읽어와서 출력한다. 아래와 같이 get_text() 함수를 쓰는 경우와 쓰지 않는 경우를 비교해 보자
print(title) // html 태그를 포함해서 출력
print(title.get_text()) // html 태그를 제거하고 텍스트만 출력
실행해 보면 title 변수를 그대로 출력하는 경우에는 HTML 태그가 포함되어 출력되고,
get_text() 함수를 사용하면 "네이버 뉴스" 라는 titie 의 텍스트만 출력되는 것 을 확인할 수 있다
'IT > Programming' 카테고리의 다른 글
K-Fold 교차 검증 (0) 2022.01.21 Python #1] Python 개발환경 설치하기 (0) 2020.01.15 error LNK2019: unresolved external symbol "__declspec(dllimport) (0) 2009.04.17 문자열 변환 (0) 2008.11.28